I am here after a long time to pen down some thoughts for just getting back to the habit of writing. I hope I’ll be able to continue sharing my thoughts more frequently.
Since its been a while, I thought I’ll share something that is not too complicated as it might make it tough for me to get out of my inertia. So, I am going to share an opinionated way of bootstrapping a light-weight java web-application.
With new languages and features coming out for public use every now and then, it is high time that legacy languages such as Java (I may no longer be able to claim this, as Java is quickly catching up to the latests trends with more sexy language features with the new java release cycle) catch up to speed with cool features other languages/frameworks offer. There were times, when I used to spend a whole day just to kick-start a basic skeleton web app with a ton of configuration files and downloading a cryptic application server and copying my class files to weird locations. But with a lot of frameworks that support java integration, things have gotten much better.
There’s plethora of easy-to-use frameworks that has made Java backend/full-stack engineer’s life a lot better. But I’d like to share my experience on how easy it is to setup a skeleton web-app using my favorite Springboot (Although I use dropwizard for my day-to-day activities at my work for various reasons, Spring has always been my favorite framework of choice ever since my revelation about things getting easier in Java).
I can keep blabbering about Spring framework forever. But I prefer to see things in action. So let me start with my rambling!
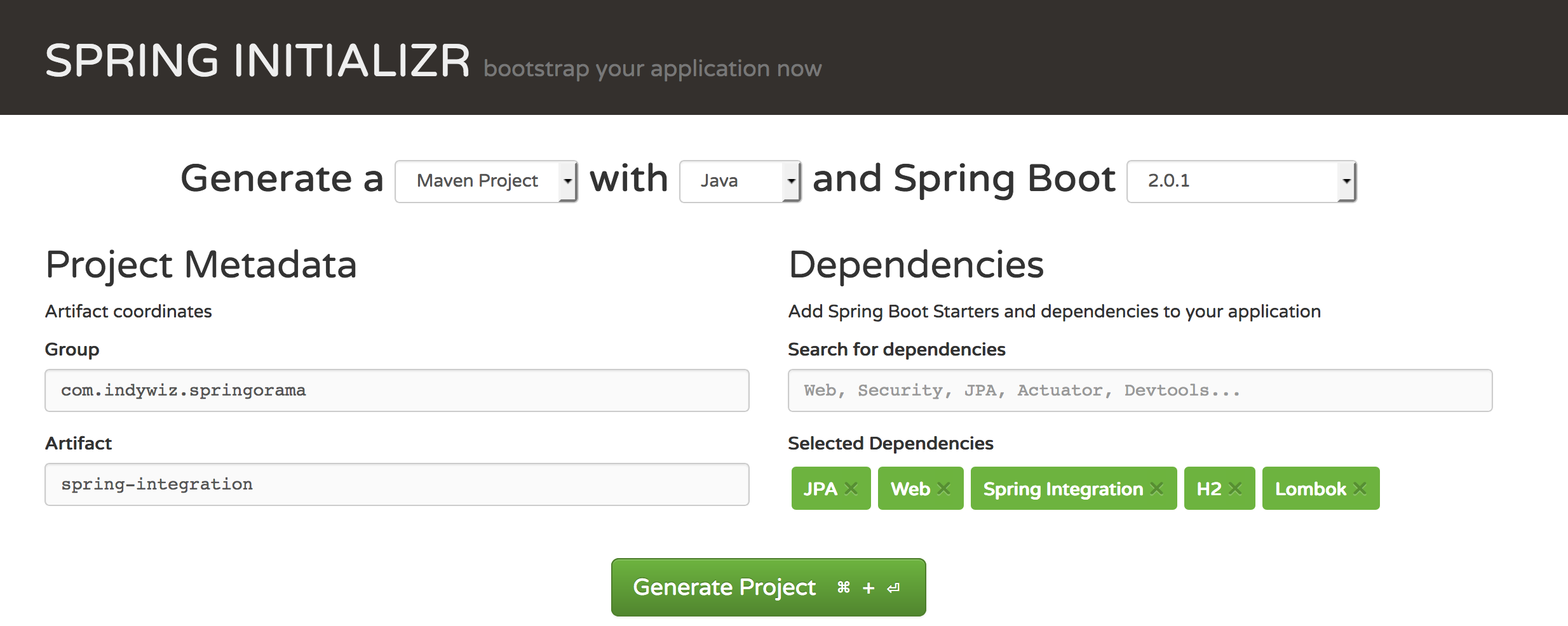
Say hi to Initializr!
The biggest pain for getting started with any framework is actually “getting started“! With spring boot, getting started is as easy as clicking a few buttons. Don’t believe me, let me introduce you to spring initializr.

For setting up a spring-boot project using spring initializr, you need to;
- Setup your build tool (We are using maven as part of this post) as described here (Ignore if you already have maven installed)
- Go to https://start.spring.io/
- Fill a form to enter metadata about your project.
- Decide on dependencies to add to your project (I did not add any for this demo).
- Click on generate!
Well, once we extract the zip file, we need to open it using any IDE (I am using IntelliJ here but I wouldn’t expect any issues with Eclipse, Netbeans, etc). Here is how your extracted project would look like.

You can find this as part of my commit here in github if you are following along with me. All you now need to do is to build the project and run the DemoApplication.java file. If you like to run it from terminal like I prefer, run the following command from your root directory.
mvn spring-boot:run

If you observe now, the app starts and shuts down immediately, let’s fix that next.
But where’s the web app?
Like I said, since we did not choose any dependency in the spring initializr page. Spring initializr assumed that we were not building a web-app and gave us the bare minimum configuration for running our app.
There is a reason why I did not choose any dependency when I bootstrapped the app. Often, when we start with an app, we do not know the exact set of dependencies we’d need to start off with. It is crucial for us to know how to add additional dependencies after we started working on the app. Easy way would be to click on the Explore button on the spring initializer web-page by choosing your dependency. Let me show how easy it is in the following gif.

Now that you’ve copied the required dependency to power a web app, let’s go ahead and change our pom.xml so we could pull in the needed dependencies for bootstrapping a web-app.
Your pom file should look like my pom file in this commit.
Great! now we need to just add some magic and we are all set. For every web-app (Restful web app), you need the following logical entities for defining your restful web service;
- HTTP method (Defines the type of operation)
- Endpoint name (Defines a name for the operation)
- Parameters & Request payload (Defines user input for processing)
- Response (Defines how the response should look like)
These four things are what we are going to define in our DemoApplication.java.

Your DemoApplication.java should look like the one I have in this commit here.
That’s it! we are done with the code changes. Build your project and run it using the same command mvn spring-boot:run and now you should logs similar to the below screenshot.

Lets now open a browser and navigate to the following url
http://localhost:8080/sayHi?name=springboot
This should print the text Hi from springboot in your browser.
Congratulations your spring-boot app is ready and running with absolutely no configuration and no external server setup.
I know this is a lot of magic, but we’ve barely scratched the surface. There is a LOT of magic going on behind the scenes. I will attempt my take on it as part of a separate post in future. So long!